macOS 14.5 と Ubuntu 24.04 で確かめた。他の Un*xes で動くかは未検証。
幅
$ tput cols
高さ
$ tput lines

このブログのテーマを自作してみました。
このテーマはお堅い(?)ソフトウェア技術書から発想しました。「プログラミング言語C」とかちょっと前のオライリーの本とかをイメージしています。背景色に書籍の紙をイメージしたクリーム色、フォントは明朝体、ボーダーラインは少なめ、文章中の強調とセクションタイトルは太字のゴシック体といった感じです。 ちなみに書籍に使われているの淡いクリーム色の紙を淡クリームキンマリというそうです。初めて知りました。
コードのシンタックスハイライトを無くしてみました。技術書にはシンタックスハイライトがついていないことも多く、それを真似してみました。ただコメントには色をつけました。
package main import ( "fmt" "math/rand" "time" ) func main() { for i := 0; i < 10; i++ { dur := time.Duration(rand.Intn(1000)) * time.Millisecond fmt.Printf("Sleeping for %v\n", dur) // Sleep for a random duration between 0-1000ms time.Sleep(dur) } fmt.Println("Done!") }
go.dev/play の 「Sleep」サンプルを引用。
シンタックスハイライトを無くしてもそんなに読みづらくはないんじゃないかなと思っています。以前 Go の公式サイトにシンタックスハイライトが無いことが話題になりました。これも意識しています。とはいえ僕はコーディングするときはシンタックスハイライトが使えるなら使っています。シンタックスハイライトがあるとクオートの閉じ忘れの発見が簡単ですね。
ただ diff の出力だけは着色によって見やすさが大きく変わるので、色をつけました。
--- main.go 2024-06-17 18:00:56 +++ main_new.go 2024-06-17 18:01:22 @@ -8,7 +8,7 @@ func main() { for i := 0; i < 10; i++ { - dur := time.Duration(rand.Intn(1000)) * time.Millisecond + dur := time.Duration(rand.Intn(1000)) * time.Second fmt.Printf("Sleeping for %v\n", dur) - // Sleep for a random duration between 0-1000ms + // Sleep for a random duration between 0-1000s time.Sleep(dur)
横に長いコードを表示した時の挙動を次のようにしてみました。


全部表示にするとサイトのレイアウトが崩れることもありますが、見やすさを優先しました。ユーザーがブラウザのウィンドウを横に広げたときは広く表示されてほしいだろうからです。
長いコード列のサンプルです。
func QueryScan(ctx context.Context, db *sql.DB, query string, args ...any) iter.Seq2[scanfunc, error]
このテーマは hatena/Hatena-Blog-Theme-Boilerplate から改変して作りました。GitHub で公開しています。
テーマストアで公開しています。どうぞご利用ください。
ある URL からのレスポンスのステータスコードだけ知りたいときがある。404 かどうかだけわかればよいときだったり。
そういうときは curl の --write-out / -w オプションが使える。このオプションには %{http_status} などの変数を含んだテンプレートを渡す。このオプションを指定して実行すると、レスポンスボディが出力したあとにテンプレートを展開した文字が出力される。
たとえば、つぎのように使う。
curl -w 'status code: %{http_code}\n' example.com <!doctype html> <html> ... omitted </html> status code: 200
レスポンスボディのあとに -w に渡したテンプレート status code: %{http_code}\n が展開されたものが出力された。ステータスコードが 200 であることがわかった。
テンプレートに使える変数はいっぱいある。
シェルスクリプトでステータスコードを変数に入れるときは次のようにする。
code=$(curl -sSL -o /dev/null -w '%{http_code}' example.com)
Rust は人気なプログラミング言語である。 しかしながら今は Rust は Plan 9 での実行をサポートしていない。
したがって Plan 9 で Rust で書かれたプログラムを実行するには、コンパイラを移植するといった大変な作業が必要かと思っていた。しかしながら Wasm を使うことで、特に苦労なく実行することができたので紹介する。
この試みは ![]() id:lufiabb が Plan 9 でも Rust を動かせるようにしようと言っていたがきっかけである。
id:lufiabb が Plan 9 でも Rust を動かせるようにしようと言っていたがきっかけである。
Ubuntu 23.10 がインストールされた AMD64 マシン上で作業している。Plan 9 はQEMU上で実行している。 Plan 9 の OS イメージと Plan 9 向けの Go (Go 1.21 binaries) は 9legacy.org からダウンロードしている。
wasm ファイルを生成するのはホストの Linux 上で行った。僕はあまり Rust と Wasm について詳しくないので、下の説明をそのまま実行した。
ここでつくったプログラムは次のことをする。
Hello world! と書き出す。/helloworld/helloworld.txt を生成して、そのファイルに Hello world! と書き出す。生成された wasi_hello_world.wasm を QEMU 上の Plan 9 へ送る。
Plan 9 に wazero をインストールする。
wazero は Pure Go で記述された Wasm runtime である。 Pure Go のおかげで何も修正せずに Plan 9 で動いた。 go.sum が空っぽなのがすごい。
普段 Linux や Mac で Go のアプリケーションをインストールするのと同じように、 Plan 9 上で次のコマンドを実行する。
go install github.com/tetratelabs/wazero/cmd/wazero@latest
さて実行しよう。 以下は Plan 9 のターミナル上で行ったもの。
% mkdir helloworld
% wazero run -mount `{pwd}^:/ wasi_hello_world.wasm
Hello world!
% cat helloworld/helloworld.txt
Hello world!
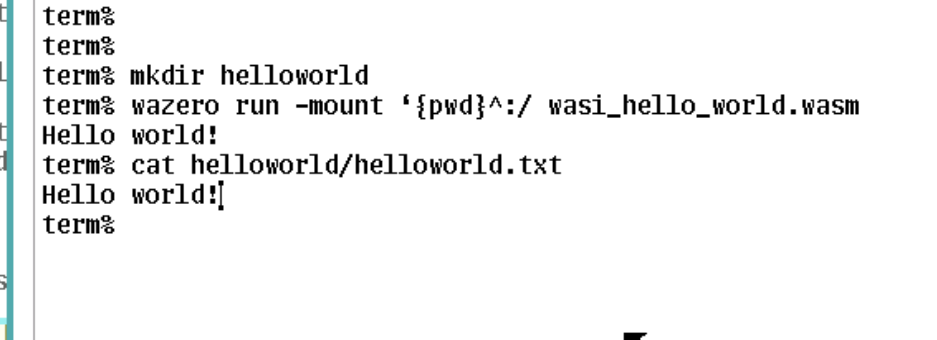
このようにとくにコードにパッチを当てずにそのまま実行することができた。
Rust コードを Wasm へのコンパイルを Linux 上でやっているのが、微妙な感じである。できれば Plan 9 上でコンパイルしたい。
Plan 9 はネットワークなどもファイルシステムで表現されているので、すでにいまの WASI (preview 1) でネットワークも扱えるのではないか。
このWasm を使った方法によって Plan 9 をサポートしない他の言語で書かれたアプリケーションも Plan 9 で動くのではないか。
Go 1.22 から実験的機能として Range Over Func が実装された。 このブログでは Range Over Func とは何か、どういうものなのか、といった説明はしないので、知らない人は次のページを見てほしい。
標準パッケージの database/sql で RDB を Query するのはボイラープレートまみれになる。
database/sql のドキュメントにあるサンプルコードは次のようになっている。
rows, err := db.QueryContext(ctx, "SELECT name FROM users WHERE age=?", age) if err != nil { log.Fatal(err) } defer rows.Close() names := make([]string, 0) for rows.Next() { var name string if err := rows.Scan(&name); err != nil { log.Fatal(err) } names = append(names, name) } // Check for errors from iterating over rows. if err := rows.Err(); err != nil { log.Fatal(err) }
https://pkg.go.dev/database/sql#example-Rows から引用。
このコードは長い。 error チェックを3回もしているのが大きな要因だ。さすがに SELECT 文の実行という定型的なことに毎回こんなコードを書きたくない。面倒だ。
だから、このサンプルコードのような (*DB).QueryContext と (*Rows).Next と (*Rows).Scan の一連の流れを、関数として独立して、いかなるクエリでもボイラープレートを書かずに済ましたい。以下このような関数の名前を QueryScan にする。
よし、 QueryScan を書こう!
func QueryScan(ctx context.Context, db *sql.DB, query string, args ...any) ... { ...??? }
…って、あれ?この関数の実装ってそんな簡単じゃない?
そう、自明ではない問題がいくつかある。
もっとも大きな問題は (*Rows).Scan の引数がクエリごとに違うこと。型も引数の数もクエリごとに違う。これらの情報をどうやって渡すの?そして返り値の型はどうするの?
reflection つかうの?あれ面倒くさいなこれ。となる。
普通の開発ではサードパーティの SQL ライブラリを使うのがいいんだろうけど、今回それは置いておこう。また reflect パッケージで頑張ってつくるのも今回はしない。QueryScan 関数は画面に収まる程度にしたい。
このブログではそれらの問題を Range Over Func を使うことで、まあまあ解決した関数 QueryScan を提案する。それは (*DB).QueryContext と (*Rows).Next の一連の流れを、関数としてまとめたものだ。
提案する関数は次のように定義される。
type scanfunc func(dest ...any) func QueryScan(ctx context.Context, db *sql.DB, query string, args ...any) iter.Seq2[scanfunc, error]
この関数の実装は後で紹介する。
そして QueryScan 関数を使うと、このブログで最初に提示したサンプルコードは次のようになる。
names := make([]string, 0) for scan, err := range QueryScan(ctx, db, `SELECT name FROM users WHERE age=?`, age) { if err != nil { log.Fatal(err) } var name string scan(&name) // scan には返り値がない。返り値を無視しているわけではない。 names = append(names, name) }
うおおおおおお
error のチェックが3回から1回に減って、コード行数も16 行から 9行に減っている。 コードが短い分読みやすいのではないだろうか。
この関数のポイントとしては (*Rows).Scan 自体は結局手で書かないといけないところだ。エラーの返り値がないラップされた関数 scan を使っているので多少は楽になっているものの、この部分の面倒さは残る。しかしながら、 (*Rows).Scan の引数がクエリごとに違うという問題は解決している。
では QueryScan はどのような実装になっているのだろうか。中身を見てみよう。
type scanfunc func(dest ...any) // 再掲 func QueryScan(ctx context.Context, db *sql.DB, query string, args ...any) iter.Seq2[scanfunc, error] { return func(yield func(scanfunc, error) bool) { rows, err := db.QueryContext(ctx, query, args...) if err != nil { yield(nil, err) return } defer rows.Close() for rows.Next() { var scanErr error if !yield(func(dest ...any) { scanErr = rows.Scan(dest...) }, nil) { return // ここは困る!scanErr が渡せないからだ。後述する。 } if scanErr != nil { yield(nil, scanErr) return } } if err := rows.Err(); err != nil { yield(nil, err) return } } }
QueryScan の実装は、最初に引用した pkg.go.dev にあるサンプルコードと似ていることに気がつくだろうか。むしろほとんど一緒である。違うのは (*Rows).Scan (をラップした関数)と error を yield に渡しているところだ。
yield 関数が呼ばれるたび、 range over func の for 文の中身が1回実行される。言い換えると、for のループが1回まわる。QueryScan の db.QueryContext とそのエラー処理をしているところに注目してみよう。つぎの部分だ。
rows, err := db.QueryContext(ctx, query, args...)
if err != nil {
yield(nil, err)
return
}
yield が1回だけ実行されるので、 QueryScan のユーザー(呼び出し側)から見ると、ループが1回だけまわって終了しているように見える。このループで渡される値は、(nil, err) だ。つまりエラーだけを渡している。
yield を呼び出している別のところも見てみよう。たとえば、 rows.Scan が失敗するとどうなるのか?
あるループの中で、 scan が失敗すると、次にもう1回だけ scanErr を渡すためのループが実行される。yield(nil, scanErr)の部分だ。そしてループは終了する。
QueryScan の問題点提案しておいてなんだが、この QueryScan は面白いものの、Range Over Func のハックだなぁとは思う。オーバーエンジニアリングかもしれない。また問題点もある。
大きな問題点は、for で error が渡されたときだけ break すると仮定していることだ。 error が渡されたループで break するのは問題はない。(というか error が渡されたときは最後のループなので、 break してもしなくても同じだ。)しかしながら、正常系つまり nil error が渡された時に break されると困ることがある。なぜなら次のループで、 error が渡されるかもしれないが、それを無視することになるからだ。 前述した QueryScan の実装で「ここは困る!」とコメントした部分だ。
for scan, err := range QueryScan(...) { if err != nil { log.Print(err) break // ここの break は問題がない。 return でもよい。 } ... // もしかすると、次のループで error が渡ってくるかもしれない。 // ここで break するとその error チェックができない。 break }
このような break をするケースはほとんどないだろうけど。
一応解決策はある。それは break ができてしまう range over func をやめること。この記事の前提を崩すように見えるが、そんなこともない。QueryScan の返り値を iter.Seq2 すなわち
func(yield func(scanfunc, error) bool)
ではなく、
func(yield func(scanfunc)) error
で書くということだ。 Range Over Func は yield の返り値の bool で break かどうか分岐していた。 yield の返り値がなくなったので、 break できなくなった。また error をかえす場所を変えた。後者をかえす QueryScan の実装は宿題とする。
for 文では書けなくなるが、考え方自体は変わっていない。たとえば次のように呼び出すことになる。
err := QueryScan(ctx, db, `SELECT name FROM users WHERE age=?`, age)(func(scan scanfunc) { var name string scan(&name) names = append(names, name) })
こっちの方が好きな人がいるかもしれない。こちらはbreak の問題がなくなり、エラーの渡し方も標準的だ。僕もこっちの方が好きかもしれない。
まあこのブログは新機能の range over func をせっかくなら使ってみたという欲張りがあったので、最初は range over func を使った手法を紹介したのだった。
スライスのソートを維持したまま要素を追加する関数 appendSorted の実装
func appendSorted[S ~[]E, E cmp.Ordered](s S, e E) S { i, _ := slices.BinarySearch(s, e) return slices.Insert(s, i, e) }
s = []int{} s = appendSorted(s, 4) // [4] s = appendSorted(s, 1) // [1 4] s = appendSorted(s, 9) // [1 4 9] s = appendSorted(s, 5) // [1 4 5 9] s = appendSorted(s, 3) // [1 3 4 5 9] s = appendSorted(s, 11) // [1 3 4 5 9 11]
配列の長さを とすると、BinarySearch は
, Insert は
だから、 appendSorted は
。一方、単純に append と sort する実装だと、
だから、早くなっている。平衡二分木を使えば、もっと早くなりそうだけど、コードも短いし十分実用的でしょう。
この記事ははてなエンジニア Advent Calendar 2023の 12月36日 2024年1月5日の記事です。
Mackerel をファイルシステムにしてみましょう。 Mackerel でファイルシステムを監視するのではありません。 Mackerel をファイルシステムにするのです。
じゃん
mackerelfs と言います。よろしくおねがいします。 github.com
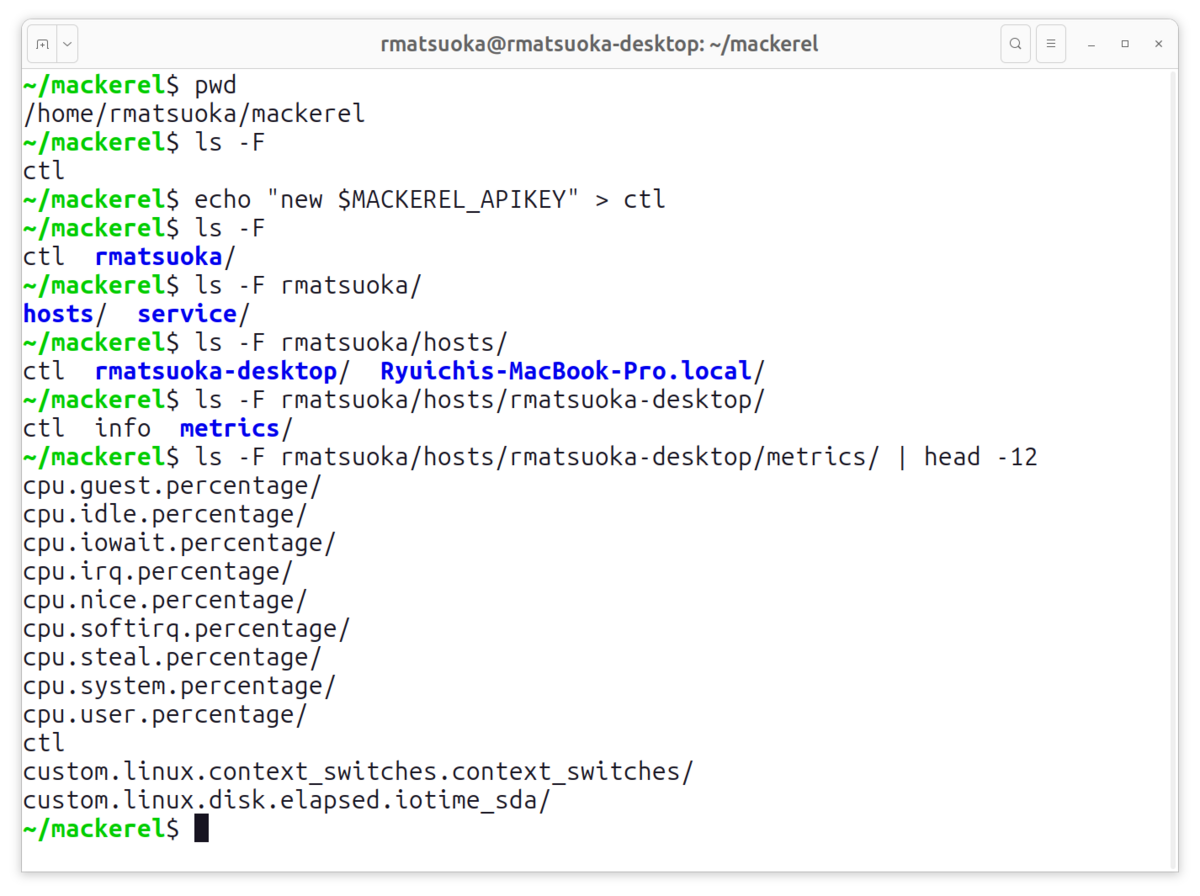
/home/rmatsuoka/mackerel ディレクトリに mackerelfs をマウントしましょう(マウントの方法は後半説明します。)最初は ctl ファイルだけがあります。
$ ls -l total 0 --w--w--w- 1 rmatsuoka rmatsuoka 0 Jul 14 2042 ctl
さて Mackerel を操作するときは API キーが必要です。 mackerelfs にも API キーを登録しましょう。ここでは私のオーガニゼーション rmatsuoka のものを使います。登録するには ctl ファイルに以下のように書き込むだけです。
$ echo "new $MACKEREL_APIKEY" > ctl
すると mackerel ディレクトリに rmatsuoka というディレクトリが登場しました。
$ ls -l total 0 --w--w--w- 1 rmatsuoka rmatsuoka 0 Jul 14 2042 ctl dr-xr-xr-x 1 rmatsuoka rmatsuoka 0 Jul 14 2042 rmatsuoka
$ ls -1F rmatsuoka/
hosts/
service/
rmatsuoka/hosts 以下にはホストがディレクトリとして一覧になっています。
$ ls -1F rmatsuoka/hosts/
ctl
rmatsuoka-desktop/
Ryuichis-MacBook-Pro.local/
このオーガニゼーションでは私用の端末 rmatsuoka-desktop, Ryuichi-MacBook-Pro.local を監視しています。
rmatsuoka-desktop のメトリック一覧は hosts/rmatsuoka-desktop/metrics を readdir すれば、ファイル(ディレクトリ)として見ることができます。
$ ls -F rmatsuoka/hosts/rmatsuoka-desktop/metrics/ cpu.guest.percentage/ cpu.idle.percentage/ cpu.iowait.percentage/ cpu.irq.percentage/ cpu.nice.percentage/ cpu.softirq.percentage/ cpu.steal.percentage/ cpu.system.percentage/ cpu.user.percentage/ ctl custom.linux.context_switches.context_switches/ custom.linux.disk.elapsed.iotime_sda/ ...
<metric_name>/1hour 以下にあるファイルを読むと過去一時間分のメトリックが取得できます。ホストのカスタムメトリックと同じ形式になっています。
ホストのカスタムメトリックを投稿する - Mackerel ヘルプ
$ cat rmatsuoka/hosts/rmatsuoka-desktop/metrics/cpu.system.percentage/1hour cpu.system.percentage 5.542648 1704379920 cpu.system.percentage 5.857077 1704379980 ...
metrics/service を readdir しましょう。サービス一覧が見ることができます。このオーガニゼーションには devices というサービスがあります。
$ ls -1F rmatsuoka/service/
ctl
devices/
devices のロール(ここでは desktop と laptop)とサービスメトリックは rmatsuoka/service/devices 以下にあります。
$ ls -1F rmatsuoka/service/devices/
ctl
desktop/
laptop/
metrics/
$ ls -1F rmatsuoka/service/devices/desktop/
ctl
memo
rmatsuoka-desktop/
ちなみにディレクトリの至るところにある ctl ファイルに reload と write するとそのディレクトリの情報を reload してくれます。
$ echo reload > rmatsuoka/service/devices/ctl
見終わったので、 rmatsuoka オーガニゼーションを mackerelfs から取り除きましょう。mackerelfs のルートにある ctl に書き込むだけです。
$ echo delete rmatsuoka > ctl $ ls ctl
mackerelfs はファイルシステムですが、データを収納するストレージではありません。Mackerel の情報を取得するアプリケーション / インターフェースです。
古くから Unix の「ファイル」とは単にデータの塊を指すだけではなく、デバイスのインターフェースでもありました。今の Unix-like な OS でも /dev 以下にデバイスファイルがありますね。これによってユーザーからはファイルもデバイスも open, read, write など同じ方法で扱うことができます。この考えを更に推し進めた Plan 9 はコンピュータ上のプロセスや、ネットワーク、アプリケーションまで様々なリソースを(ファイルではなく)ファイルシステムとして表現しました。これによって「ネットワークにアクセスする」、「プロセスを見る」といった処理は専用のシステムコールではなく open, read などのファイル用のシステムコールで賄えるようになります。 Linux でもプロセスは /proc 以下にファイルシステムで表現されています。/proc があるおかげで Linux, Plan 9 の ps コマンドはシンプル(つまり /proc 以下にあるファイルを読むだけ)になっています。一方 /proc がない他の Unix-like では ps コマンドは SUID がついていて強力な権限でゴニョゴニョしている。
mackerelfs は Plan 9 のアプリケーションから着想を得てつくりました。Mackerel のホストやサービスといった情報はファイルにマッピングされ、ユーザーはファイルを操作するシステムコールだけで Mackerel をの情報を取得することができます。
ところでアプリケーションの UI / UX という観点から mackerelfs を見てみましょう。このブログの前半では mackerelfs を使ってみた様子を紹介しました。そこでは ls や cat, echo のように Unix の基本的なコマンドで完結しています。ファイルシステムなので当然ですね。Unix に慣れた人なら、すぐ使えるのではないかなと思います。 ctl ファイルの挙動は独特ですが。
Mackerel には mkr というCLI アプリケーションがあります。これもシンプルな操作で CLI から Mackerel を操作することができますが、一定程度使い方を学ぶ必要があります。
さらに mackerelfs は、ファイルIO をつかって簡単にスクリプトを組み、操作を自動化させることができます。コマンドラインで行ったことをそのままスクリプトに書き起こせばよいので、手動と自動の間に連続性があります。また http リクエストができない AWK をつかってスクリプトを組むこともできます。
#!/usr/bin/awk -f BEGIN { while (getline < "rmatsuoka/hosts/rmatsuoka-desktop/metrics/cpu.system.percentage/1hour")) { ... } } ...
このようにファイルシステム型のアプリケーションは基本的なコマンドのみで操作が完結したり、自動化しやすかったりの特徴をもっており、使いやすいツールのカタチとしての可能性があると思います。
mackerelfs は
func FS() fs.FS
という関数だけが用意されたライブラリです。 fs.FS は Go の標準パッケージ io/fs に定義されたファイルシステムを抽象化したインターフェースです。
fs.FS は標準パッケージの定義ですから、 fs.FS をコンピュータにマウントするサードパーティライブラリはいくつか存在すると思います。 例えば僕が作った ya9p は fs.FS をPlan 9 のファイルシステム通信プロトコル 9P2000 によって操作できます。mackerelfs にはこの ya9p を使ったコマンド mackerel9p が用意してあります。
Linux, macOS などは 9P2000 は 9fans/plan9port にある 9pfuse を使えば FUSE 経由でマウントできます。(macOS で FUSE を使うには macFUSE も必要です。)
$ go install github.com/rmatsuoka/mackerelfs/cmd/mackerel9p@latest $ mackerel9p
$ mkdir mackerel $ 9pfuse 'tcp!localhost!8000' mackerel